原文: Building Effective AI Agents \ Anthropic
我们与多个行业中数十个构建大型语言模型(LLM)智能体的团队有过深入合作。我们发现,最成功的系统并非依赖复杂的框架,而是建立在简单、可组合的构建模式之上。
过去一年中,我们在多个行业与客户团队协作,共同构建 LLM 智能体系统。我们的经验表明,优秀的实现方案往往摒弃冗杂设计,转而采用简洁、模块化的架构。
本文基于我们在客户合作和内部研发中的实践经验,旨在为开发者提供构建高效智能体系统的实用指导。
什么是智能体?
“智能体”(agent)这一术语有广泛定义。一些用户将其理解为具备完全自主能力、能够调用外部工具并长期运行的系统;另一些用户则将其用于描述严格遵循预设流程的自动化系统。
在 Anthropic,我们将这两类系统统称为智能体系统(agentic systems),但在架构上加以区分:
- 工作流(Workflows):通过预设代码路径,将 LLM 与外部工具组合协调;
- 智能体(Agents):由 LLM 自主决策任务流程与工具调用方式,动态规划任务执行路径。
下文将详细介绍这两类系统的特点与实现方式。附录1还将展示两个实际应用场景。
何时(不)应使用智能体?
构建 LLM 应用时,我们建议从最简单的方案起步,仅在实际需求推动下再引入更复杂的系统设计。换言之,很多情况下其实不需要构建完整的智能体系统。
尽管智能体系统可提升任务完成效果,但往往以增加延迟与成本为代价。因此,是否采用智能体,需结合具体应用场景做出权衡。
- 工作流适用于结构化、流程明确的任务,具备高可预测性;
- 智能体更适合任务复杂、流程灵活、需要模型主导决策的大型应用场景。
在很多应用中,单轮 LLM 调用结合**检索增强(RAG)与上下文示例提示(few-shot prompting)**已能满足业务需求。
是否应使用框架?
当前市面上已有多种框架可用于构建智能体系统,如:
- LangGraph(LangChain)
- Amazon Bedrock 的 AI Agent Framework
- Rivet:可视化构建 LLM 工作流
- Vellum:用于设计和测试复杂提示流程的 GUI 工具
这些框架在任务管理、工具集成、调用链编排等方面提供了便利,加快了原型开发速度。但它们也引入了额外抽象层,容易导致:
- 提示词与响应流程不透明,难以调试;
- 无意中增加系统复杂性;
- 对底层机制理解不足,从而埋下 bug 隐患。
我们的建议是:优先直接使用 LLM API 构建系统。许多构建模式仅需几行代码即可实现。如果决定使用框架,务必理解其底层逻辑。
可参考我们的 Cookbook 示例代码,了解具体实现方式。
构建模块、工作流与智能体
下文介绍我们在生产环境中观察到的常见 LLM 系统构建模式。我们从最基础的构建块“增强型 LLM”开始,逐步过渡到完全自主的智能体。
增强型 LLM(Augmented LLM)
LLM 是智能体系统的核心,通过增强能力(如检索、工具调用、记忆等)实现扩展。我们当前的模型已能主动:
- 发起搜索请求;
- 选择恰当工具;
- 决定保留哪些信息。
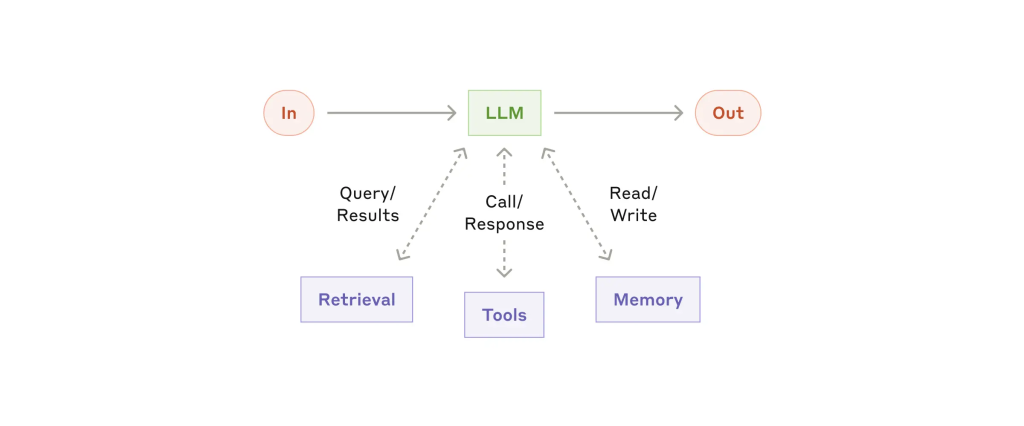
实践建议:
- 根据具体应用场景定制增强功能;
- 为 LLM 提供清晰易用的接口与详细文档。
我们推荐使用新的 Model Context Protocol,它能通过简洁的客户端实现方式,将第三方工具生态集成进 LLM 系统中。
后续工作流模式均假设每次 LLM 调用具备上述增强能力。
工作流模式(Workflows)
1. 提示链(Prompt Chaining)
将任务拆分为多个步骤,每步由一次 LLM 调用完成,可在中间步骤加入校验节点。
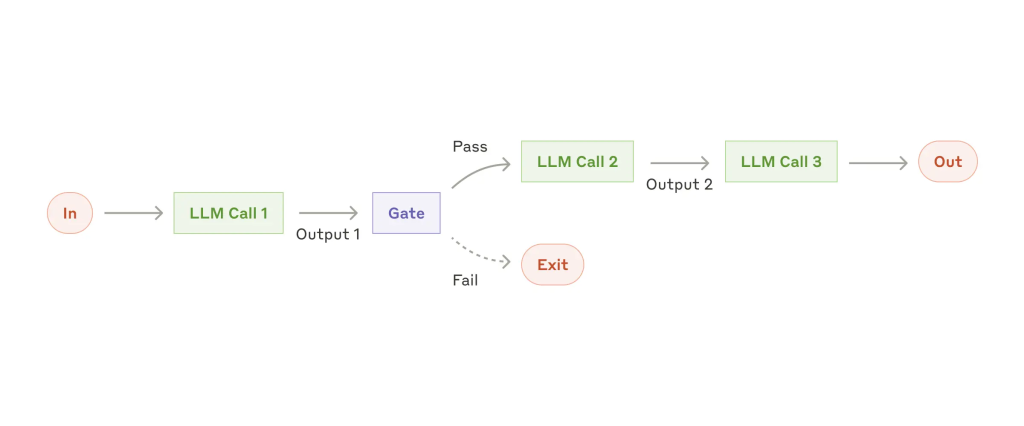
适用场景:
任务可自然分解为固定子任务;通过分步处理提升精度,降低单步复杂度。
示例:
- 生成营销文案 → 翻译成多语言;
- 写作流程:编写大纲 → 验证 → 生成文档内容。
2. 路由(Routing)
根据输入类型将请求分配至特定子流程或提示模版,提升准确性与可控性。
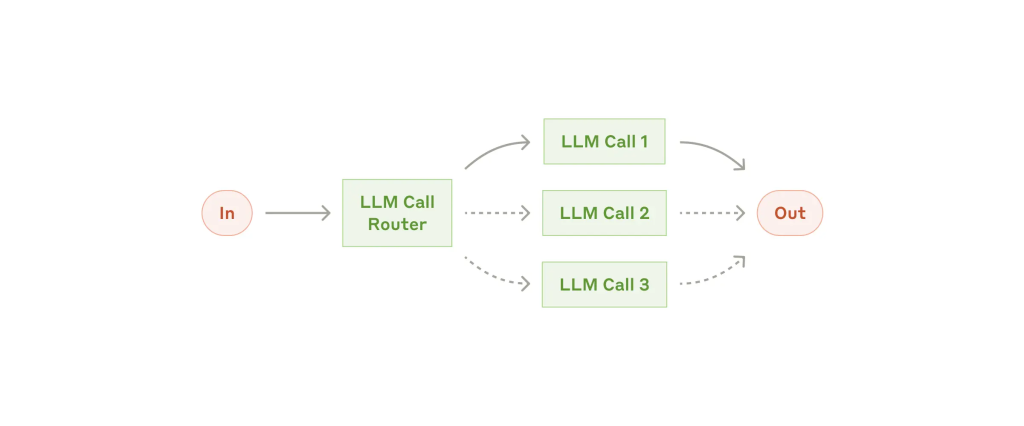
适用场景:
输入类型明确、分类准确率高。
示例:
- 客服场景:将请求分为常见问题、退款、技术支持;
- 多模型路由:简单请求用 Claude 3.5 Haiku,复杂请求交由 Claude 3.5 Sonnet 处理。
3. 并行化(Parallelization)
将任务拆分为可并行处理的子任务,或对同一任务进行多轮生成以聚合结果。
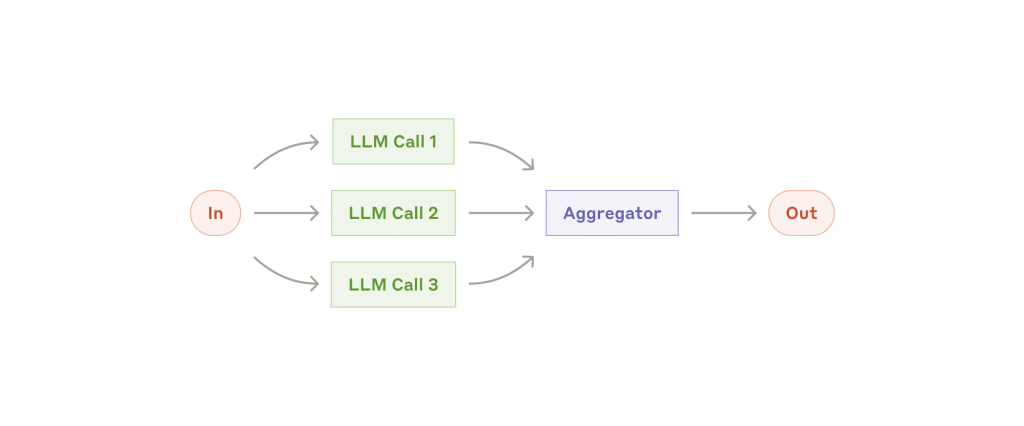
子模式:
- 分段处理(Sectioning):任务拆解为子部分并行完成;
- 投票机制(Voting):多模型或多轮生成后取最佳输出。
示例:
- 分段:模型1响应用户,模型2进行审核;
- 投票:多个模型对代码漏洞进行复查。
4. 调度-工人模型(Orchestrator–Worker)
一个主 LLM 拆解任务、调度多个子 LLM 并整合结果。
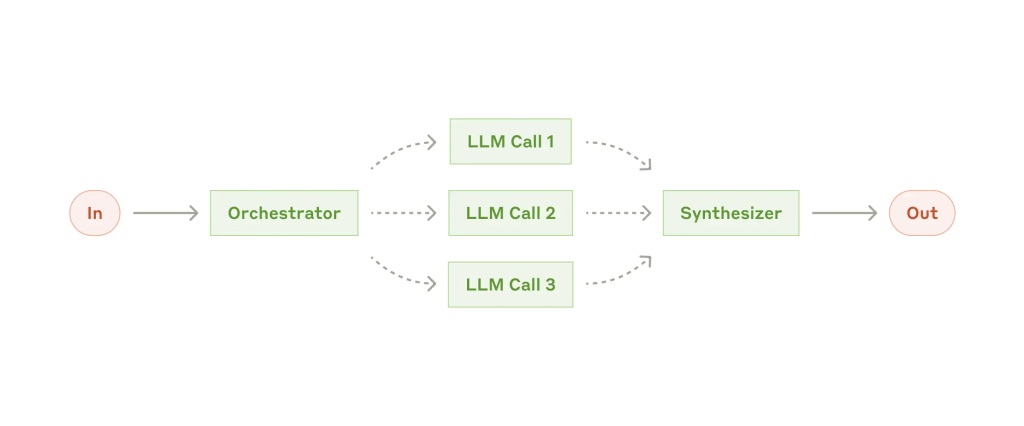
适用场景:
任务结构不固定,需动态拆解与执行。
示例:
- 修改多文件代码;
- 从多信息源抓取并分析相关数据。
5. 评估器–优化器(Evaluator–Optimizer)
一个 LLM 生成候选结果,另一个 LLM 负责评估并提出反馈,循环迭代优化。
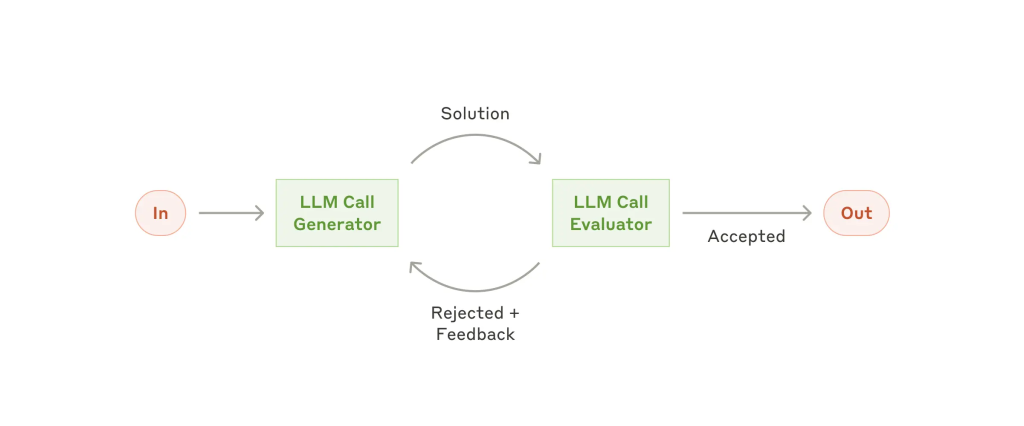
适用场景:
评估标准清晰,迭代提升带来显著收益。
示例:
- 文学翻译质量优化;
- 多轮信息检索并验证是否足够完整。
智能体(Agents)
随着 LLM 的能力演进,智能体已可实际部署,其核心能力包括:
- 理解复杂输入;
- 推理与计划;
- 稳定使用工具;
- 执行中的错误恢复。
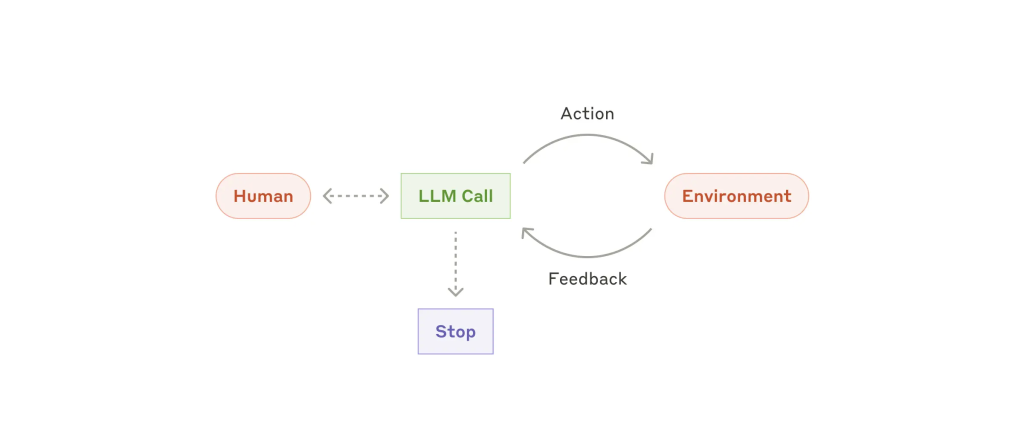
典型流程如下:
- 智能体接收用户任务,必要时追问确认;
- 自主规划并执行流程;
- 根据工具反馈与执行结果调整行为;
- 在关键节点或遇阻时可请求人工介入;
- 支持设置最大循环次数等终止机制。
关键点:
实现方式往往不复杂,核心在于让 LLM 在循环中使用工具。设计良好的工具集与清晰的接口文档是成功关键。
智能体适用场景与注意事项
适用场景:
- 无法预判任务步骤;
- 需要模型自主调度和灵活执行;
- 环境受控,可容错、可调试。
风险与注意事项:
- 成本较高;
- 错误可累积放大;
- 建议在沙箱环境充分测试,并加装安全机制。
示例:
- 代码智能体:在 SWE-bench 数据集上自动完成跨文件任务;
- Claude 自动操作计算机:可执行点击、搜索等 GUI 任务。
模式组合与定制
上述模式不是彼此排斥的固定方案,而是可灵活组合的通用构建块。
我们建议遵循以下策略:
- 从简单提示入手;
- 使用系统化方法评估系统效果;
- 仅在验证必要性后引入复杂系统。
总结
LLM 系统的成功关键在于是否真正解决了问题,而非复杂度。构建过程中建议秉持以下三项原则:
- 保持设计简单清晰;
- 显式展示模型的决策与规划过程;
- 精心设计 Agent-Computer Interface(ACI),保证工具接口文档完备、测试充分。
框架适合探索与原型阶段,但建议在生产部署中移除多余抽象,基于基础组件构建系统,从而实现高性能、易维护、稳定可信的智能体。
鸣谢
本文由 Erik Schluntz 与 Barry Zhang 撰写,基于我们在 Anthropic 构建智能体系统的经验,并感谢众多客户的反馈与建议。
附录1:实践中的智能体应用
我们发现以下两个场景充分体现了智能体系统的价值:
A. 客户支持
特点:
- 对话驱动的自然交互流程;
- 可接入客户信息、订单历史、知识库等外部工具;
- 能执行退款、更新工单等自动操作;
- 成效易量化,如“问题解决率”。
部分公司已采用按“问题解决计费”的智能体定价模式,反映出高度信任。
B. 编码智能体
软件开发是 LLM 应用最具潜力的领域,已从补全扩展至完整问题解决:
- 问题定义清晰;
- 可通过测试验证结果;
- 模型可迭代优化方案;
- 输出质量具备客观度量指标。
在 SWE-bench Verified 中,智能体可根据 PR 描述完成完整开发任务。但需注意,即使通过自动测试验证,人工审查仍对系统一致性至关重要。
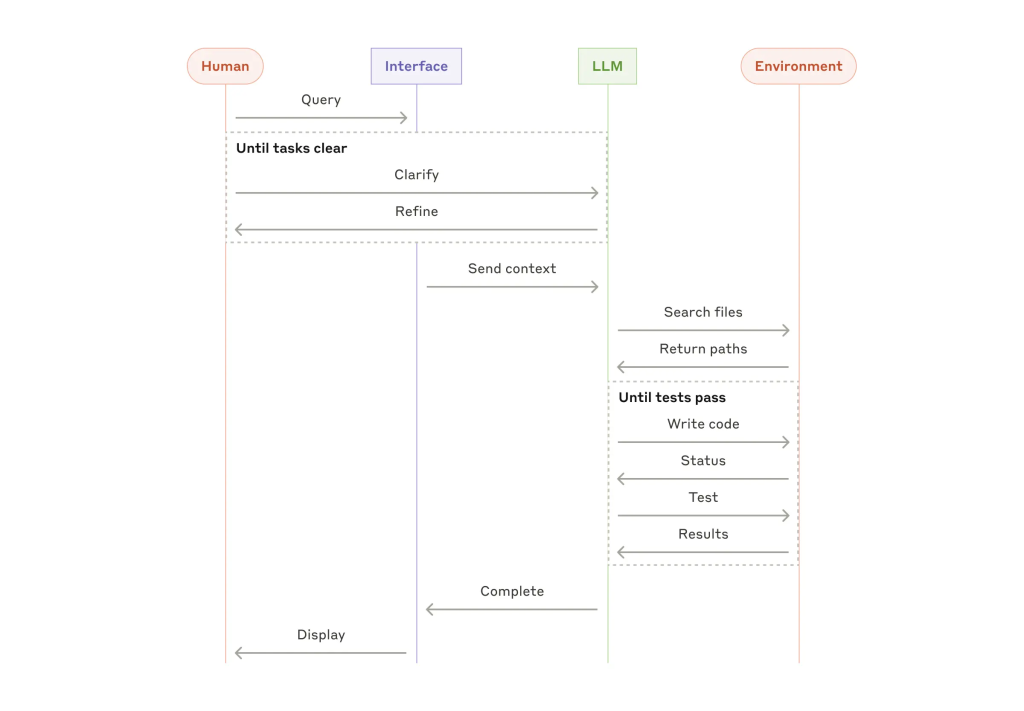
附录2:工具的提示词工程(Prompt Engineering your Tools)
在智能体系统中,工具通常是关键组成部分。Claude 与外部服务交互需遵循明确的工具结构定义。在响应中,模型会生成 tool use 块以调用工具。
实践观察:
- 同一任务有多种表达方式,例如编辑文件可使用 diff 或全文件重写;
- 输出格式(如 JSON、Markdown)影响模型表达能力;
- 格式复杂性直接影响输出质量与易用性。
建议:
- 给模型留足“思考空间”,避免格式限制过多;
- 使用模型熟悉的自然表达格式;
- 避免高格式开销(如复杂换行、转义、大量行号追踪)。
将 ACI(Agent–Computer Interface)视作等同于 HCI(Human–Computer Interface)重要的系统设计部分。
优化实践建议:
- 换位思考参数命名与描述是否直观清晰;
- 编写接口文档时面向低经验开发者;
- 用多样化输入测试模型对工具调用是否稳定;
- 增加防错机制(如强制使用绝对路径)减少出错概率。
在构建 SWE-bench 智能体过程中,我们为优化工具定义所投入的时间甚至超过了主提示词的设计。